
Abstract:
In drug manufacturing, keeping track of data is crucial for the drug’s approval from the FDA. The “Continued Process Verification” (CPV) data needs to be maintained for ensuring that the product outputs are within predetermined quality limits. In spite of rising demand for the creation of digital data directly at the source itself, some companies follow the traditional methods of documenting the processes parameters on paper, on designed forms. This leads to data being inaccessible for others unless it is again digitized by someone. The traditional way of achieving this is to have someone enter the data into a computer system by shuffling around the pages in the document. The manual process consumes a lot of time and leaves very little time for the data entered to be validated. This article briefly describes the possible methods of automating the manual data entry process, and how the upcoming technologies can be used for this work.
Introduction
Converting handwritten and typed data from papers into digital formats is one of the most commonly faced challenges across industries today. Keeping data on papers has its own set of limitations like limited accessibility, searchability, using data for analytics, etc. The digital transformation of such documents is necessary. Over a while, companies have adopted various methods of converting this data into a digital structured format. Some companies hire interns to manually enter the data from the document into excel sheets or word documents, while some companies need the scientists working on the projects to manually enter this data into digital documents. The manual data entry process consumes valuable time and effort from the scientists while explaining the entire process of data entry to new interns consumes time from the team. With advancements in the software industry, there have been multiple attempts to solve these problems, but each solution comes with its own set of limitations. Robotic Process Automation (RPA) is one of the closest successful solutions in helping companies convert their data from papers to structured digital formats. RPA relies on the rules that the documents might follow. The papers are scanned and processed as an image in the RPA software. The software tries to identify the set of parameters on the image, which need to be translated into the structured database. The set of parameters is searched based on certain rules of the document, which could be the sequence of pages, the sequence of words on the pages, or some other form of a landmark for identifying the parameters on the paper. This approach mostly fails if the paper documents do not follow any template, or there exist multiple pages with similar contents, or if most of the contents on the paper are handwritten. Considering the dynamic nature of the documents, it becomes difficult for the software to define rules based on which the process can be completely automated. Many solutions/software rely on Optical Character Recognition (OCR) engines as one of the primary components in their toolbox, which is further combined with techniques from the Natural Language Processing (NLP) domain, to try to make sense of the extracted texts. But many solutions fail due to the inability of the OCR to provide accurate results on scanned pages containing hand-written texts, special symbols, marking, notes, etc. This leads to breaking the flow of a possible fully automated solution.
The following sections talk about various possible OCR engines from the leading firms in the market and try to explore and evaluate the performances of the OCRs specifically on hand-written texts. Further, an experiment is performed to try to integrate the OCRs with custom-built software that can use the OCR output and try to structure the data from scanned pages into a database. The pros and cons of this approach are explained in subsequent sections. Furthermore, to overcome the shortfalls of OCR technology, an alternate approach is suggested, using Speech-to-text for data extraction. The speech-to-text approach is also integrated within a custom-built software to evaluate the efficiency of data extraction, in terms of speed and accuracy. The speech-to-text based solution is further investigated on its scalability aspect, and how much time and effort would be needed per batch records are calculated.
Experimental Setup
The main objective of the experiments was to study and analyze the best possible approach in automating the data extraction process from scanned documents archived in PDF formats, which would also include the handwritten texts.
Data: The experiment is performed on a set of sample scanned PDF files. Each PDF file would represent one batch-record. Multiple batch records are obtained from the same CMO and for the same drug, which would make sure that all the PDFs have the same parameters, which can be extracted from them. Also, this ensures that all the PDFs try to closely follow a certain template, which can be thus used in automated software.
OCR Evaluations: The experiment started with the evaluation of the performance of various state-of-the-art commercial and open-source OCR engines, and the implementation of various methods to achieve better performances using image processing techniques. The OCRs are evaluated based on factors like ease of use in the BioTech and Pharmaceutical Industry; and the accuracy of performance. Commercial OCRs included in this experiment include Google Vision APIs, Amazon Textract, and Abbyy FineReader, while Tesseract OCR will be used under the open-source OCR category. Based on the performance achieved from the OCRs and its applicability in the BioTech and Pharmaceuticals industry, the next steps would be decided.

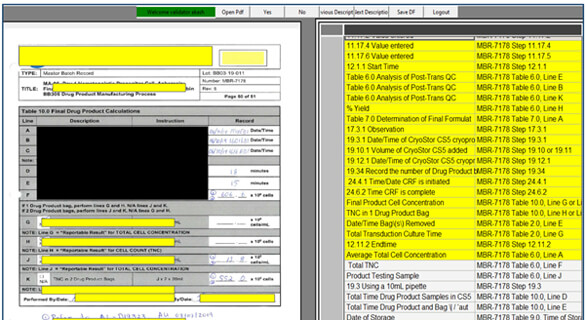
Speech-to-text / Speech Recognition: The Speech-to-text solution is analyzed for its applicability in the industry, and the solution is evaluated based on the performance achieved in terms of accuracy of data extraction and speed of data extraction by performing a time study. For evaluating the achievable speed via speech-to-text based data extraction system, the software is created for the workflow which allows to user to choose the PDF files and load extraction metadata, and auto navigates using an intelligent page finding algorithm, simultaneously allowing the user to record his words for data entry into the database against a parameter, thus automating the data structuring process. The time study is performed on five batch records, where each batch record is split into three PDFs. Each PDF denotes a stage in the drug manufacturing process.
OCR Assessment
The OCRs selected for the experimental study included Google Vision, Amazon Textract, Abbyy FineReader, and Google’s open-source Tesseract OCR engines. To evaluate the performance of the OCRs, 20 pages from the batch record PDFs in the form of images, were sent to each OCR after cropping the images to sections containing only handwritten information and the obtained text was compared to the ground truth texts which were recorded manually for these pages. The standard text-to-text comparison algorithms were used, in which two strings are compared with each other based on character-wise similarities. The results from the first evaluation are tabulated below.

It can be observed that Google Vision’s API service provides the best results on the handwritten texts but is capable of giving results with only 66.7% accuracy. In the BioTech and Pharmaceuticals domain, the achieved accuracy is much lower than desired, as the information is very sensitive to safety factors. To improve the accuracy of Google’s options, i.e. Vision API and Tesseract, we can perform image enhancement techniques, which would provide better images for the OCR, and hence the OCR output accuracy can be improved.
The image processing techniques involved with document processing were implemented as a pre-processing step. Techniques like image sharpening, contrast and brightness adjustments, noise removal, etc. were implemented, and the same images were again passed on to the OCRs. These image improvement techniques proved beneficial for the Tesseract OCR but reduced the accuracy of Vision API. The accuracy from Google Vision API reduced from 66.7% to 60%, but for Tesseract OCR the accuracy increased from 33.5% to 44.1%. This showed that one cannot rely solely on the image processing techniques, but the improvements in the OCR engine itself were required. As Google’s Vision API is a third party solution, one has no control over the training of the system or even with data privacy. Hence, for the next round, only Tesseract OCR was considered. It was trained further on handwritten data. The handwritten sections from the PDFs were split into train and test. The training data was used for further training of Tesseract OCR, while the test data was used for evaluating the OCR performance while training.
The following two images show a sample result of image processing techniques applied which resulted in the improvement of Tesseract OCR performance.

A sample of a handwritten section, before and after image processing
Tesseract OCR’s performance was measured across all the handwritten sections in the entire 5 batch records resulting in 15 PDFs of varying sizes. The average performance of the OCR on the entire documents set was observed to be 34.35% before training, while after training the Tesseract OCR results improved to 47.1%. Using OCRs which could utmost provide maximum 50% accuracy on handwritten texts cannot be used for developing an automated system.
The OCR technology has yet to reach its full maturity. There are multiple instances of the document and handwritten data variations observed in our daily activities. No doubt that the OCR technology has seen tremendous improvements in the past 5 years, but it is yet to become independent of variations like different handwritings, font sizes, shades of ink, image noise and associated garbage values, bordered and borderless tables, etc. It is due to these limitations of the OCR technology, that a completely or partially automated solution cannot be developed.
Speech-to-Text
The speech-to-text conversion software is matured enough and can produce results with 90-95% accuracy in the achieved text outputs. The performance can be further improved up to 100% if the speech recording is made in a silent environment and the pace of speech and accent is maintained. The Google Cloud Speech service was initially used but was found to be slowing down the process of data extraction, as it needs the audio to be first recorded and saved in a file, which is then sent to the cloud service and it returns a text output. The text output is provided to the data entry system, which takes care of the text being allocated to the correct parameter. The audio file needs to be recorded for each data point, which makes the entire operation of the data fill-up process very slow.
As an alternative, Speech-to-text software running locally can be used. The workflow is created to integrate the speech-to-text method into data extraction and data entry software. The following diagram denotes the workflow of the software for new batch-record processing.
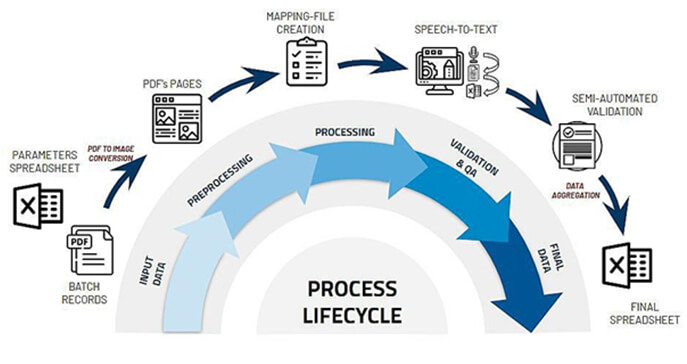
The speech-to-text approach is integrated into software that can take care of the remaining workflow for data entry into a database format. The input to the workflow is the PDF and a list of parameters that need to be extracted from PDF. The pages in the PDF are converted into images for ease of processing. A mapping file is created which can map the parameters found in the PDFs to the associated page within the PDF. The pages of interest are brought to the user for each parameter so that the user can start reading the information on the page for the parameter. The speech-to-text software running in the background keeps listening to the voice and starts creating the equivalent text in a text file. Once all the parameters are recorded, the text file can be processed within the software to automatically fill-up the information for each parameter in a structured format. A validation step is also introduced within the software so as to allow the user to check the processed key-value pairs of information and correct the data if any errors are detected.
The results for time study are recorded over multiple iterations for all the five batch records. On an average, around 120 minutes were needed for each batch record, containing 3 PDFs each, which consisted of around 200 pages per batch and around 150 parameters to be extracted from those PDFs per batch. While an initial setup time of 5 hours was needed to create and validate the mapping file, which is a one time process for each type of CMO and Drug combination. The manual data entry operation can process one or two batch records per day, resulting in 5 to 10 batch records per week. The speed achieved via the above solution is trice of that of the manual data entry process.
Considering the above setup, and two roles involved in this process, one for data entry using speech-to-text technology, while the other for validation, we could scale-up the software to process around 30 drug manufacturing batch-records for a single CMO and Drug combination in a week.
The speech-to-text system results in nearly 100% accuracy and the system can be scaled up to work much faster than manual data entry and data validation process.
Conclusion
After comparing the various types of OCR solutions, it can be concluded that OCR solutions are not effective against the variations in handwritten texts. The maximum of 50% accuracy was achieved in the trials performed on the handwritten information in the PDFs, while the Speech-to-text solution achieved nearly 100% accuracy of data extraction using the human-in-loop method for the data validation. Speech-to-text seems to be a much viable solution in the industry, as it can outperform the current manual data entry approaches. Also, a combination of OCR (for pre-processing) and speech recognition yields an average of 5X improvement in overall processing speeds with zero/near-zero error rates.



 +1 (617) 221-5900
+1 (617) 221-5900
 Follow Us
Follow Us
